I’ve spent a lot of time at my past couple clients dealing with performance issues and the associated headaches that come with those problems. These issues come mainly from large sets of data or complicated queries running on Relational database systems. There’s been a lot of hype around MPP columnar databases in the cloud. I felt it was about time I got my hands on Amazon Redshift, Google BigQuery, Snowflake and put them to the test.
I downloaded the IMDB data set that is made publicly available. Loaded this dataset into MySQL, created star schema tables, and exported them into pipe delimited files. I then loaded those star schema tables into Oracle (Standard Edition 2 – I couldn’t afford the EE license), Redshift, Snowflake, and Google BigQuery.
Part of what I wanted to see is how much performance tuning time could be saved. So I did minimal, or what I would think of as standard, performance tuning. I basically built indexes on surrogate ids, analyzed tables, and partitioned tables where possible.
I created 5 queries for testing purposes. These queries were developed to simulate queries that a BI application would generate, or perhaps a novice developer.
- Query #1 – Average age of actors in films each year
- Query #2 – Average ratings per genre per year
- Query #3 – Top 5 regions with most title releases per year.
- Query #4 – Top 5 Genres in Japan ranked by rating.
- Query #5 – Regions that released the movie Fight Club.
So which is fastest BigQuery, Snowflake, or Redshift? Here were the performance results. MySQL was left out, because all queries took longer than 5 minutes. NOTE: I did not do any kind of concurrent user testing or system load testing. This should be a consideration when doing your own proof of concepts.
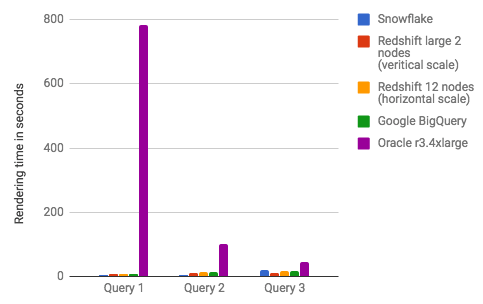
Zooming in on Redshift, Google BigQuery, and Snowflake.
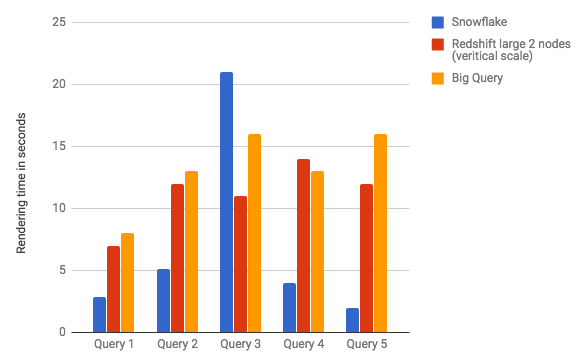
Snowflake
To me Snowflake was the clear winner. As you can see, with the exception of Query 3, it out performed the other DBs. It was the most user friendly and intuitive in my opinion. Granted it was the 4th distribution I loaded and tested, and I was getting pretty good at this by the time I worked with Snowflake. The fact remains, it only took about 2 hours to load and test the data. Most of the time was setting up S3 buckets and security in AWS.
Snowflake imported data extremely fast from S3 and without hiccups. It had its own web based SQL editor. There was no tuning done at all! Working with it just seemed a bit magical, and I don’t ever say that.
The pricing, however, I thought was a little more confusing. Snowflake uses credits. So, you have to figure out the dollar amount you are spending per credit, then how many credits per hour you are using, and add on the fee for storage. I’m not saying it’s the most expensive. I’m just saying you have to do some investigation and then some math.
RedShift
I would say RedShift came in 2nd both performance wise and with user friendliness. I would temper that with the fact that the distribution key and sort key used when building tables with this data set seemed kind of perfect. The distribution key had a very high cardinality with evenly divisible data sets. The distribution key was also the key value for 2 out of the 3 dimensions. The sort key was the Release Year field, which is used in all 5 queries. These are all good things for performance in Redshift. Without this, maybe it would not have fared as well.
User friendliness was a close second. There are some tuning considerations, and I had to search to find and download a SQL editor. Nothing too strenuous. Loading data from S3 was relatively painless and fast.
Big Query
BigQuery was a little bit of a disappointment. At first it seemed great. I loved the Google Cloud interface. Setting up my billing account and uploading data was a breeze. At the end it returned data pretty fast, and I did no SQL or DB tuning whatsoever.
Importing data was a pain compared to Redshift and Snowflake. It had trouble with special characters used in titles and names. Clearly a character encoding issue, but the Google upload interface had no clear option to select that could address the problem.
The standard SQL that I was using ran in both RedShift and Snowflake with a few edits. I expected to have to change the date function I was using to get the current year. But having to fully qualify all tables and fields was a bit of a surprise. As well as casting all values for computation. Something the other distributions did automatically.
BigQuery’s pricing model charges by the amount of data scanned. Looking at the tuning options and pricing model, it seems like BigQuery is the type of tool where you probably want to know the query patterns you are going to run and the data set you are running them on before moving them to BigQuery. For instance Partitioning/Sharding strategies are also recommended to keep costs down. I was kind of hoping for a tool that would do the partitioning and sharding for me.
Tech Notes:
I used a real data set found at imdb.com (https://www.imdb.com/interfaces/) modelled in star schema fashion. Benchmarks were done using 5 test queries. These queries were not fully optimized. This was done to simulate the sql that may be generated by a BI tool or a less experienced developer/user. Each query was ran a number of times to get an average speed. I snapshotted the instance, and rebuilt each database before running queries to rule out caching. None of the result sets are stored for quick retrieval. This is to simulate ad-hoc user queries, or systems with row level security in place, where caching is not an option.
I did not do any kind of concurrent user testing or load testing. This should be a consideration when doing your own proof of concepts.
- Query #1 – Average age of actors in films each year
- Query #2 – Average ratings per genre per year
- Query #3 – Top 5 regions with most title releases per year.
- Query #4 – Top 5 Genres in Japan ranked by rating.
- Query #5 – Regions that released the movie Fight Club.
*All time frames are limited to the 2000 to present range.
About the Data:
The Title Cast fact table is about 27.8 million rows, contains 2 surrogate IDs and 8 other fields. I used MD5 encoding for surrogate ID values to limit ELT processing overhead. This fact is on the grain of title cast, which was done in part to create a very fine grain fact.
The model contained 3 dimensions – person_d, title_d and region_r. The “r” dimension is relational, and hence will change the grain of the fact table. Using the region_r table will result in a detail data set of 40 million rows.
About the instance sizes used:
I tried to use instance sizes that would equal each other in price. Since the smallest instance of Snowflake came out to between $3-6 an hour on demand depending on whether 1 or 2 nodes were used, I tried to use sizes as close to the $3-6/hr range that I could in the other distributions.
With the RDS distributions (MySQL and Oracle) the price closest price was about $4/hr. With Redshift scaled horizontally with multiple nodes and got pretty close to $3/hr. I also scaled Redshift vertically into larger boxes, where the lowest cost was around $9.60 an hour.
There are many variables that go into pricing. You will want to do that kind of math yourself when trying to figure out which instance is best for your organization.
Tuning:
Minimal tuning was done. For MySQL and Oracle indexes were built on the Surrogate IDs and stats were gathered. MySQL was partitioned by Start Year. Unfortunately this could not be done on Oracle, because I did not have an enterprise license.
For Redshift the title surrogate key field was selected as the distribution key. For the fact StartYear was selected and ordering key. The title surrogate key seems to be about perfect as a distribution key. It is very high cardinality, and used for most joins to dimensions (region_d and title_d). Ordering key of StartYear is also a very good selection, since the field is used as a range filter in all queries. In real life these values may not be as fitting. Data was compressed during upload.
Snowflake and BigQuery there was no tuning at all done.
